Proof of Work
Every product is validated in real production environments.
Every 365UI product comes from real delivery experience — S&P 500 enterprise AI platforms, million-scale document retrieval, workflow automation, LLM inference services, messaging assistants, and edge voice products.
Read full case studiesLatest · OpenBMC upstream acknowledged
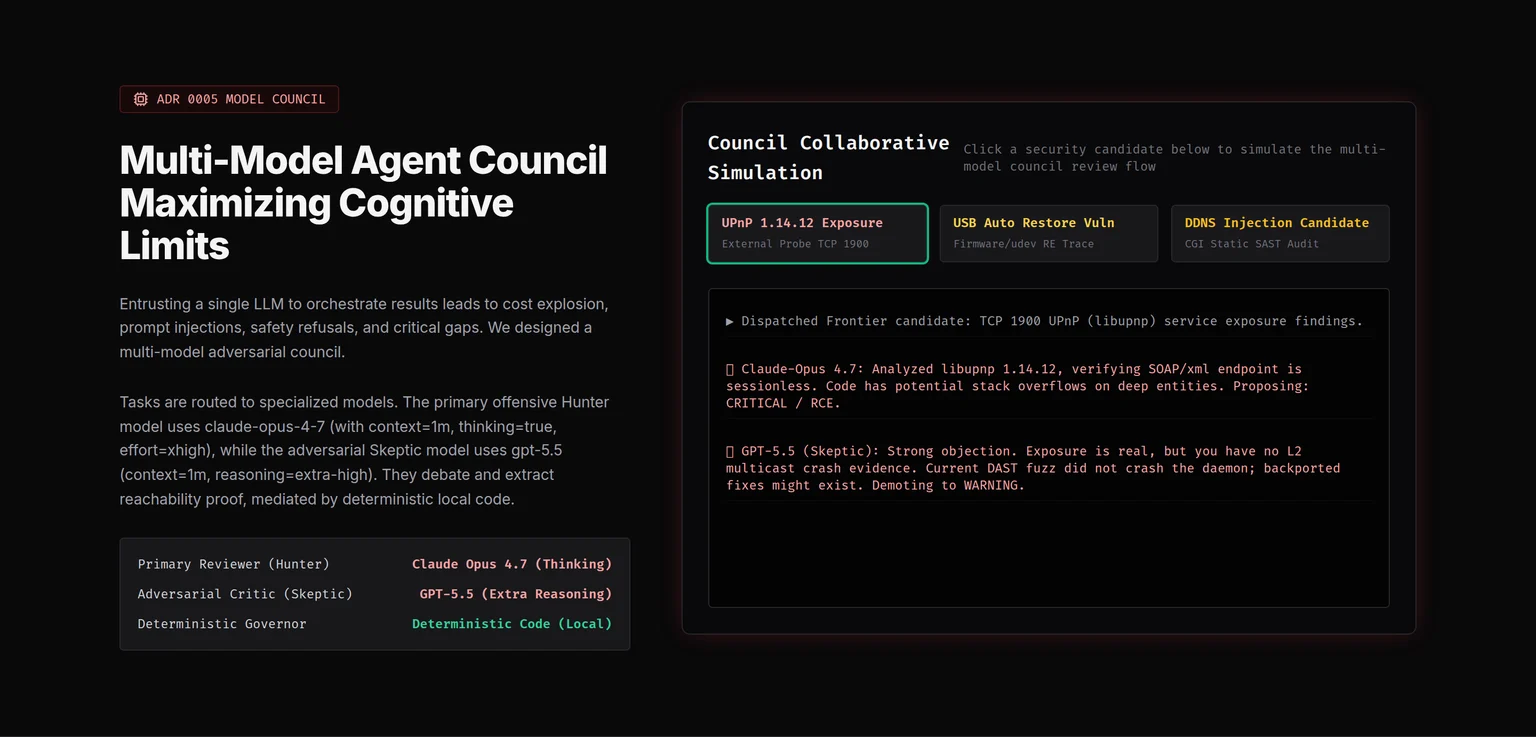
BMC Red-Team Lab
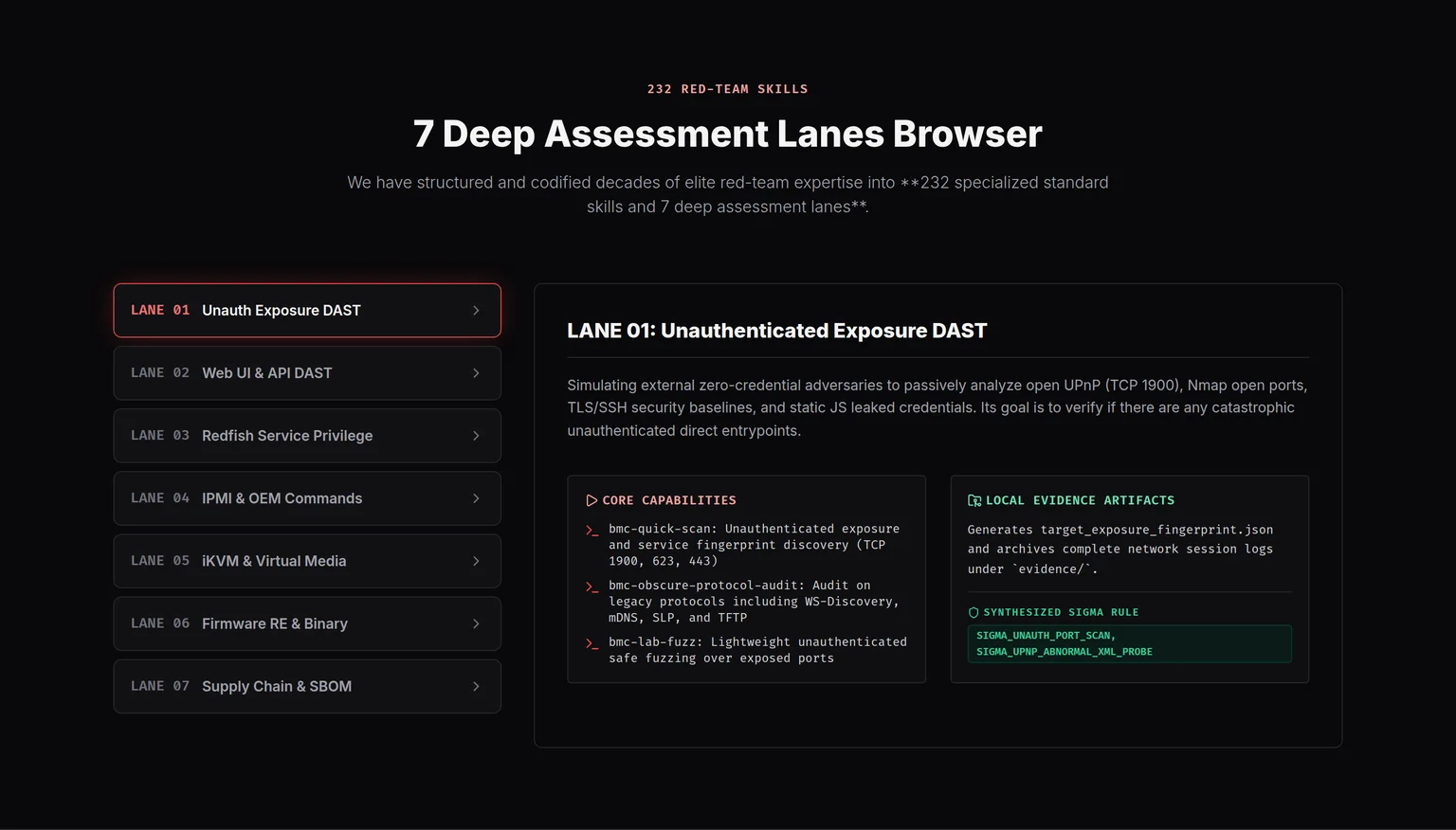
An AI-native autonomous vulnerability discovery and validation platform for server BMCs: 232 specialized skills routed across 7 deep assessment lanes, with a multi-model Council debating every candidate — Hunter (Claude Opus 4.7, Thinking) vs Skeptic (GPT-5.5, Extra Reasoning), with a deterministic-code Governor (Fail-Closed) making the final call. Every finding climbs a Proof Ladder (static candidate → deployed daemon reachability → lab reproduction → exploitability) and every offensive primitive ships with a paired Sigma detection rule. The OpenBMC `libpldm decode_get_types_resp()` report has progressed from a source-level OOB read to deployed pldmd reachability, controlled fake MCTP peer-path evidence, and a candidate fix — acknowledged upstream by the OpenBMC security team.
232 skills7 assessment lanesOpenBMC upstream confirmedProof Ladder closed-loop
Delivered to S&P 500 enterprise
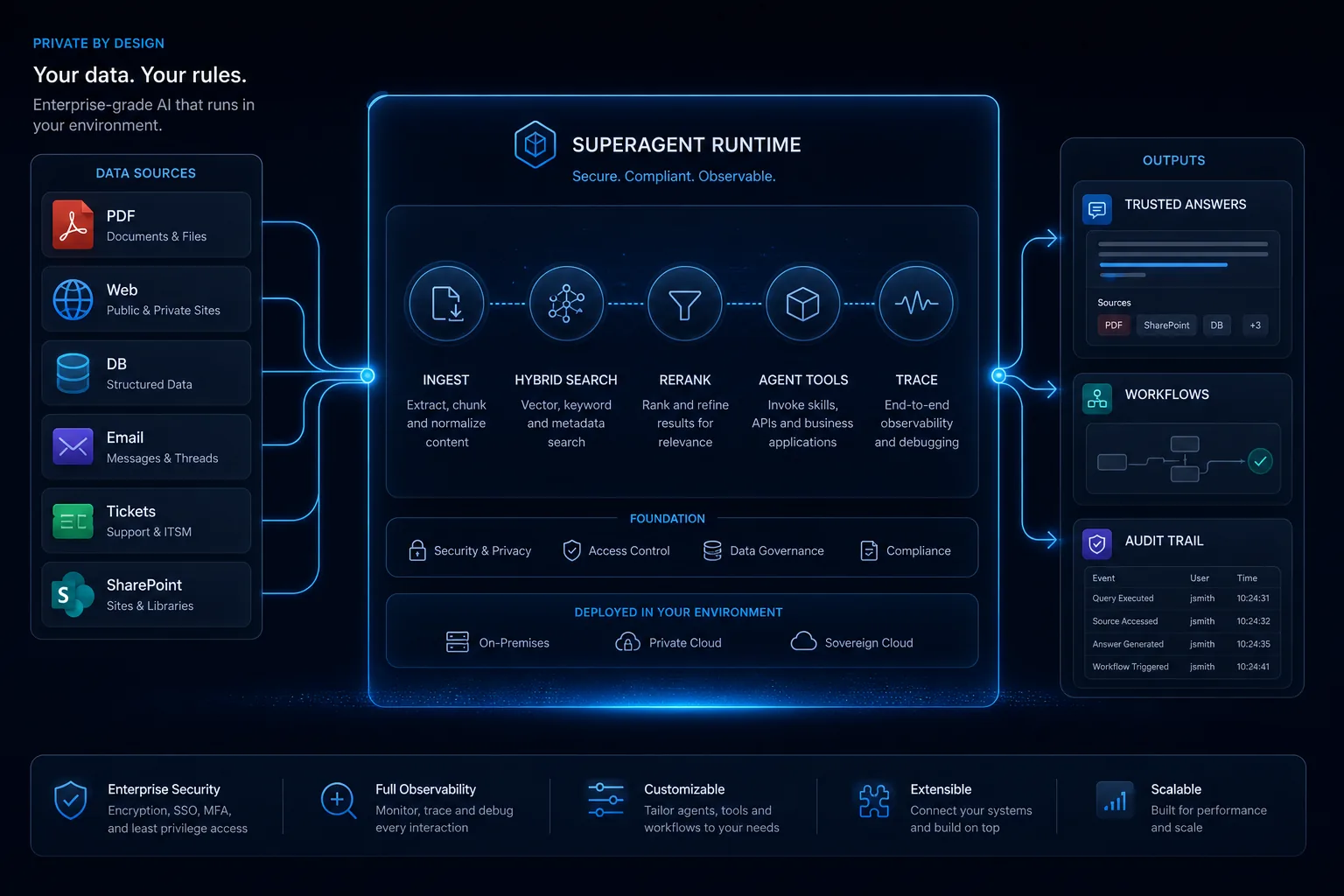
Enterprise Private AI Assistant Platform
A complete private AI assistant platform covering multi-source data ingestion (web, SharePoint, PDF/Office), multi-tenant configuration, and zero-code deployment across industries — running in production today.
In productionMulti-tenant architectureZero-code deployment
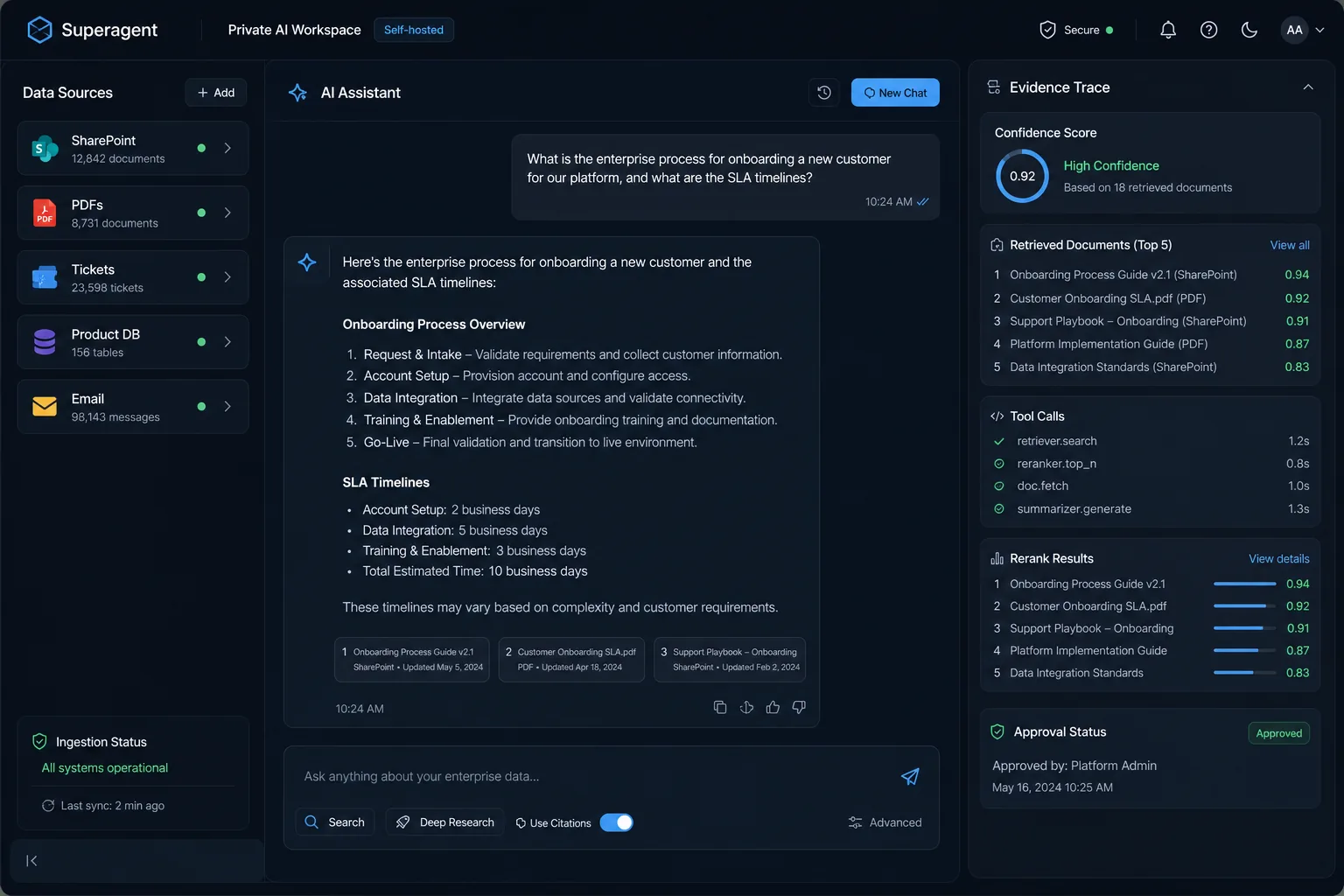
Million-scale document search
High-Accuracy Intelligent Retrieval
High-precision hybrid search over 1M+ vectors and 778K+ documents, combining semantic retrieval, keyword matching, multi-stage reranking, and multi-hop reasoning with agent-coordinated tools including database queries and web search.
1M+ vector index778K+ documents8 coordinated tools
Measurable business impact
Production Performance Optimization
End-to-end retrieval and generation pipeline optimized for production readiness: response latency reduced from 137 seconds to 6.6 seconds, data import throughput improved by 260x.
98.9% accuracy95% latency reduction260x import speed
Code quality + recruiting efficiency
Workflow Automation Agents
Large-scale operational automation: a Code-Fix Agent that resolved 12,000+ code quality issues automatically, and an AI Recruiter that extracts screening criteria from job descriptions and generates candidate shortlists on demand.
12,000+ issues resolvedAutomated JD parsingOne-click shortlists
Model selection and inference deployment
LLM Infrastructure
Comparative evaluation of 40+ leading LLMs, embedding, and reranking models, with optimized inference deployment on H100/H200/B300-class GPU clusters.
40+ model benchmarksGPU cluster inferenceEmbedding + reranker eval
Multi-person, multi-agent team standards
AI Collaboration Governance
An open-source governance framework for human-AI teams, standardizing assistant rules, architecture decision records, and lessons learned to prevent rule sprawl and context drift in multi-agent collaboration.
Layered governanceModular reuseReady to use
AI product in a closed ecosystem
Messaging Platform AI Assistant
A production AI assistant deployed inside a closed messaging ecosystem with multimodal chat, intent routing, web search, finance data, deep research, group analytics, content moderation, and an API gateway.
Live user operationsGroup analyticsAPI gateway
Ambient intelligence prototype
Edge AI Voice Assistant
A 24/7 voice assistant deployed on edge devices with full-duplex realtime conversation, persistent memory, scheduling, do-not-disturb management, and camera-based ambient awareness.
Runs 24/7Realtime voiceAmbient awareness